Try out ValidMind Academy
Our training modules are interactive. They combine instructional content with our live product and are easy to use.
This includes a new introductory notebook for mode developers, support for external models and custom functions, and many improvements to the ValidMind Platform.
Our new end-to-end notebook gives you a full introduction to the ValidMind Library.
You can use this notebook to learn how the end-to-end documentation process works, based on common scenarios you encounter in model development settings.
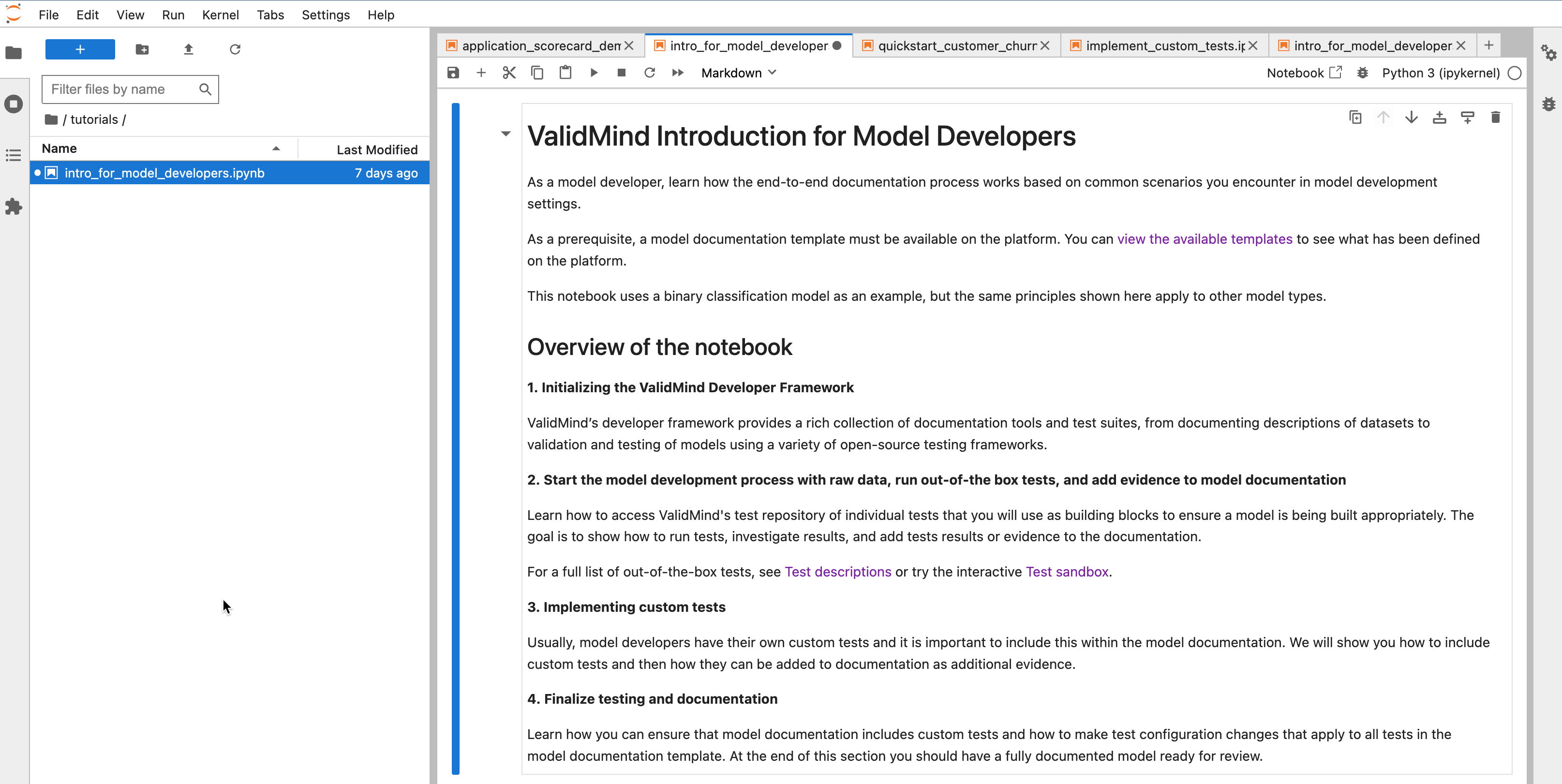
High level sections include:
1 See the full list of tests at Test descriptions or try the Test sandbox.
You can now run documentation tests without passing a Python-native model object.
This change enables you to document:
predict() interfaceTo run tests for these models, you typically must load model predictions from a file, dataset, and so on.
init_model interface does not enforce a Python model object anymore.attributes that describe the model which is required as a best practice for model documentation.Since there is no native Python object to pass to init_model, you instead pass attributes that describe the model:
# Assume you want to load predictions for a PySpark ML model
model_attributes = {
"architecture": "Spark",
"language": "PySpark",
}
# Or maybe you're loading predictions for a SageMaker endpoint (model API)
model_attributes = {
"architecture": "SageMaker Model",
"language": "Python",
}
# Call `init_model` without passing a model. Pass `attributes` instead.
vm_model = vm.init_model(
attributes=model_attributes,
input_id="model",
)Since there’s no model object available, the library won’t be able to call model.predict() or model.predict_proba(); you need to load predictions and probabilities manually.
For example:
vm_train_ds.assign_predictions(
model=vm_model,
prediction_values=prediction_values,
prediction_probabilities=prediction_probabilities,
)You can proceed to run tests on your data as you would under normal conditions, without needing to modify any other parts of your code.
We introduced a new metric decorator that turns any function into a ValidMind test that you can use in your documentation. To learn what this decorator can do for you, try our code sample on JupyterHub!
Our new Document Overview is designed to help you find the information you need more quickly.
Now more distinct from the model details landing page, the new overview page provides easier navigation and enhanced data visualization to better understand the progress of the documentation stage:
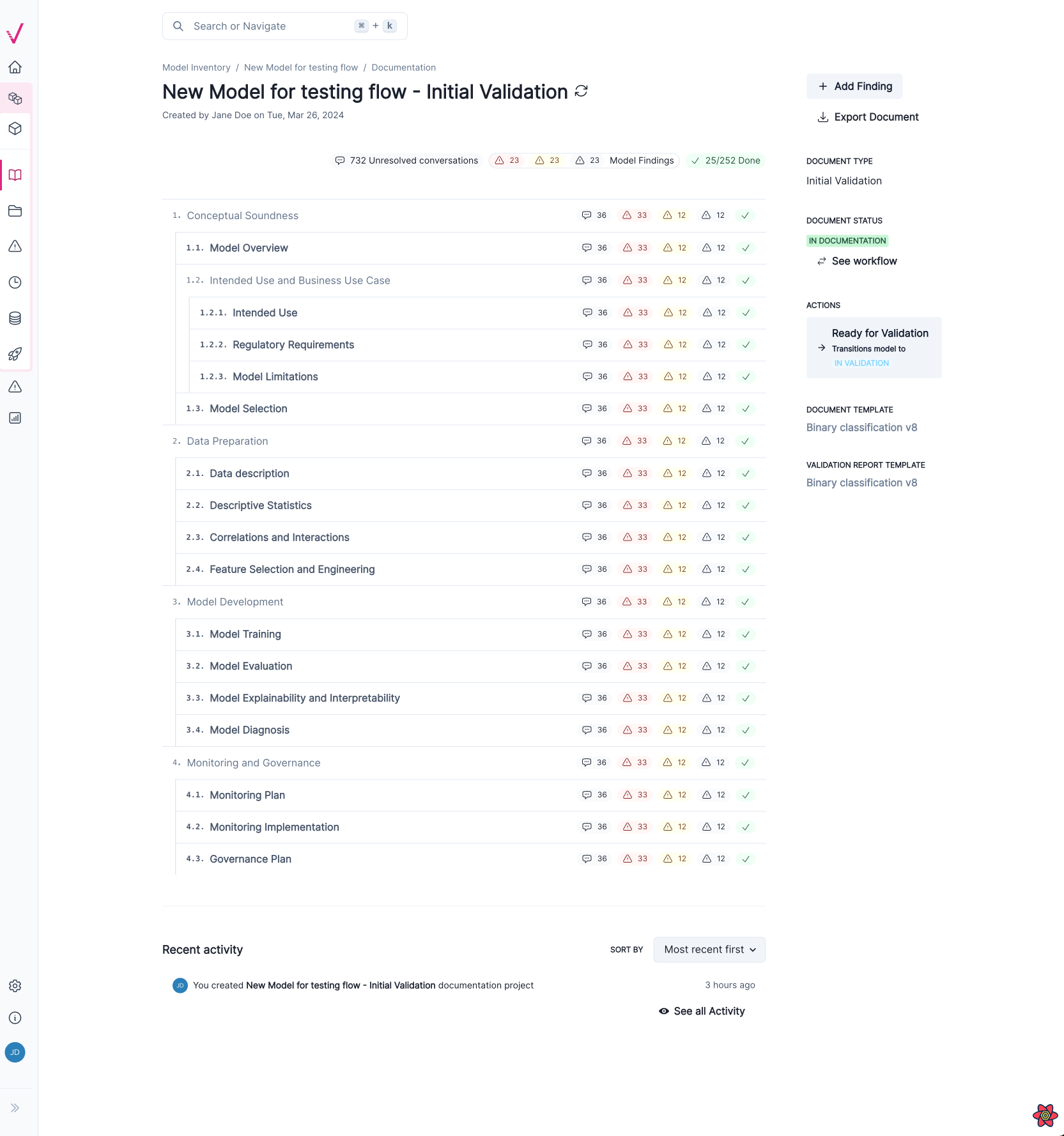
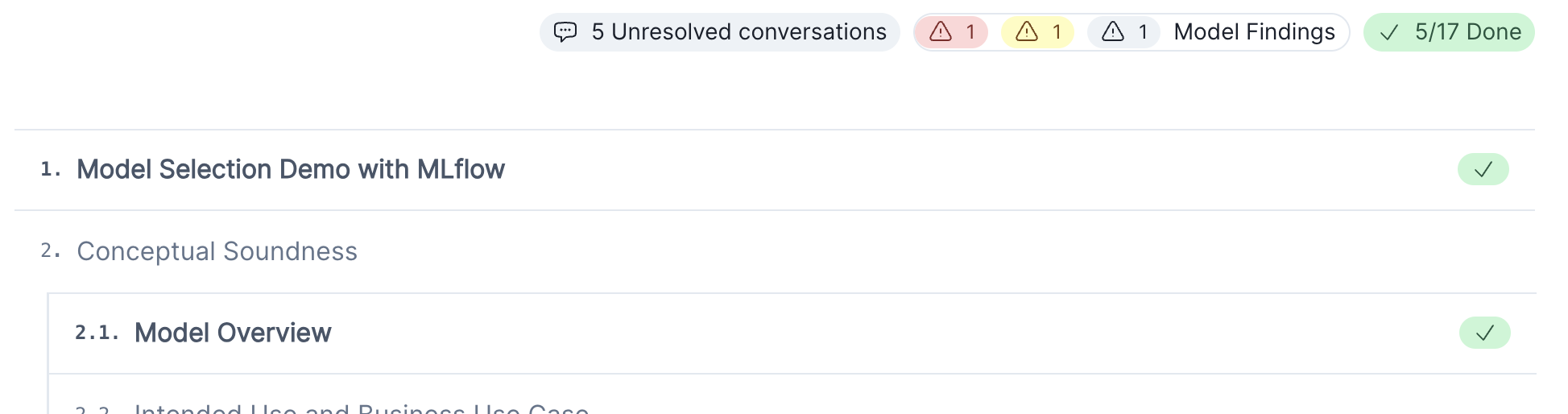
We created a new Documentation outline page which replaces the existing model overview page.
This page shows a section-by-section outline of your model’s documentation:
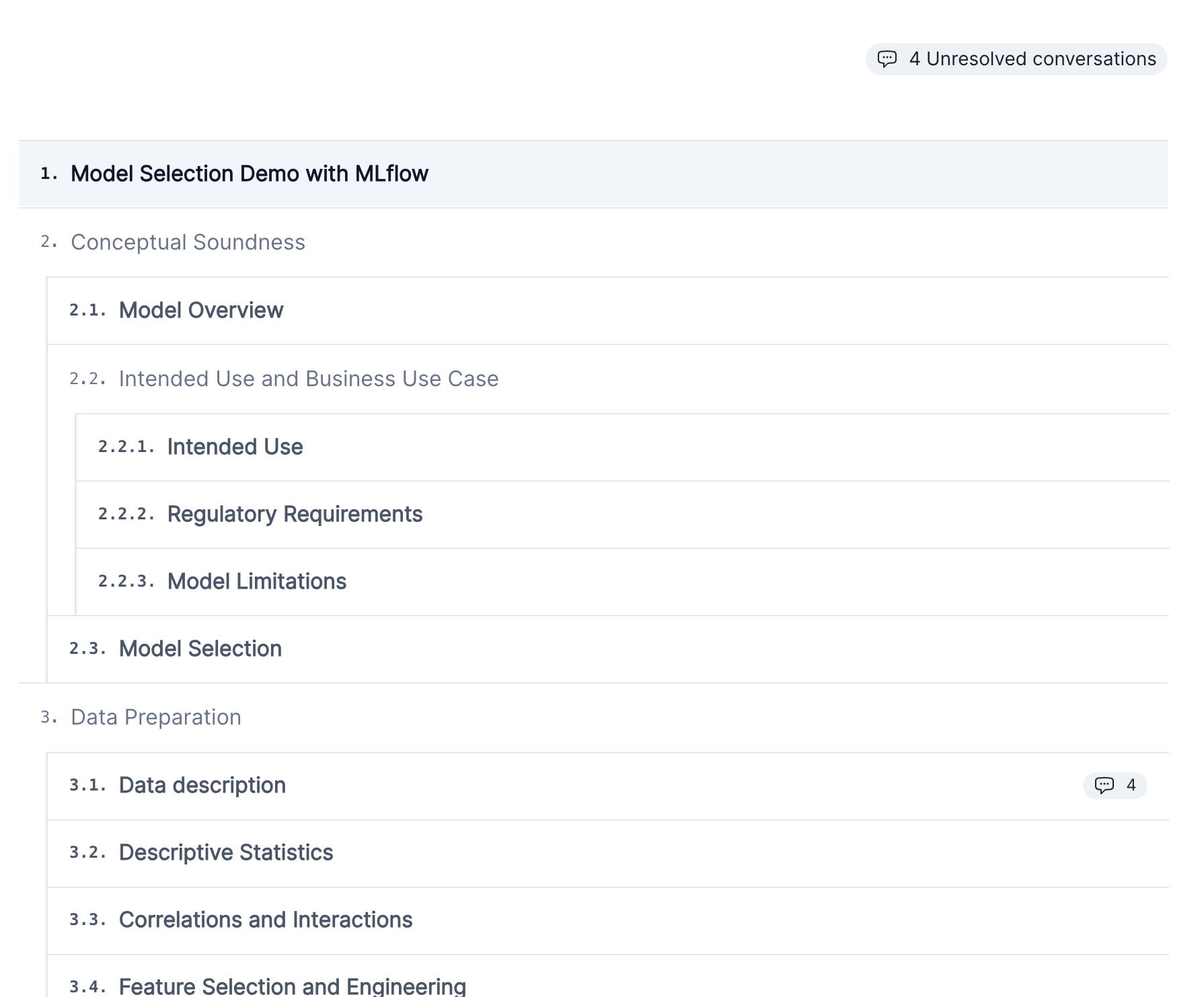
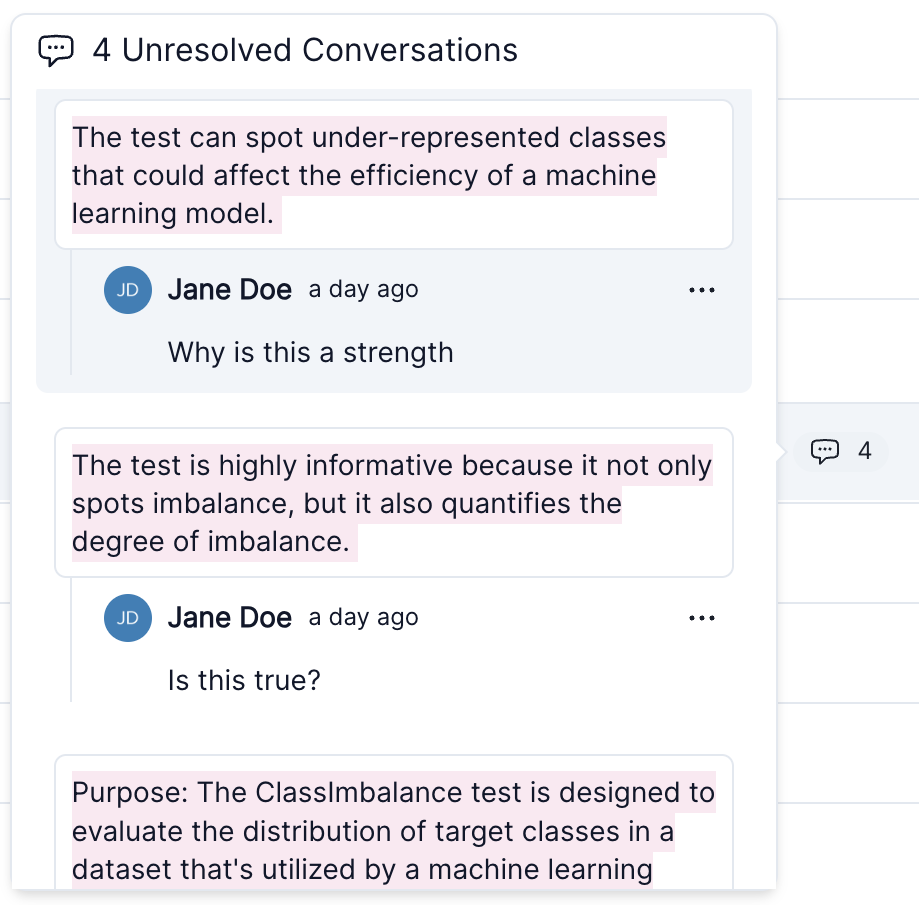
It also includes a count of every unresolved conversation within each section.
We have introduced several updates to the Organization settings page, enabling you to manage business units and risk areas for your organization.
The following features are now available:
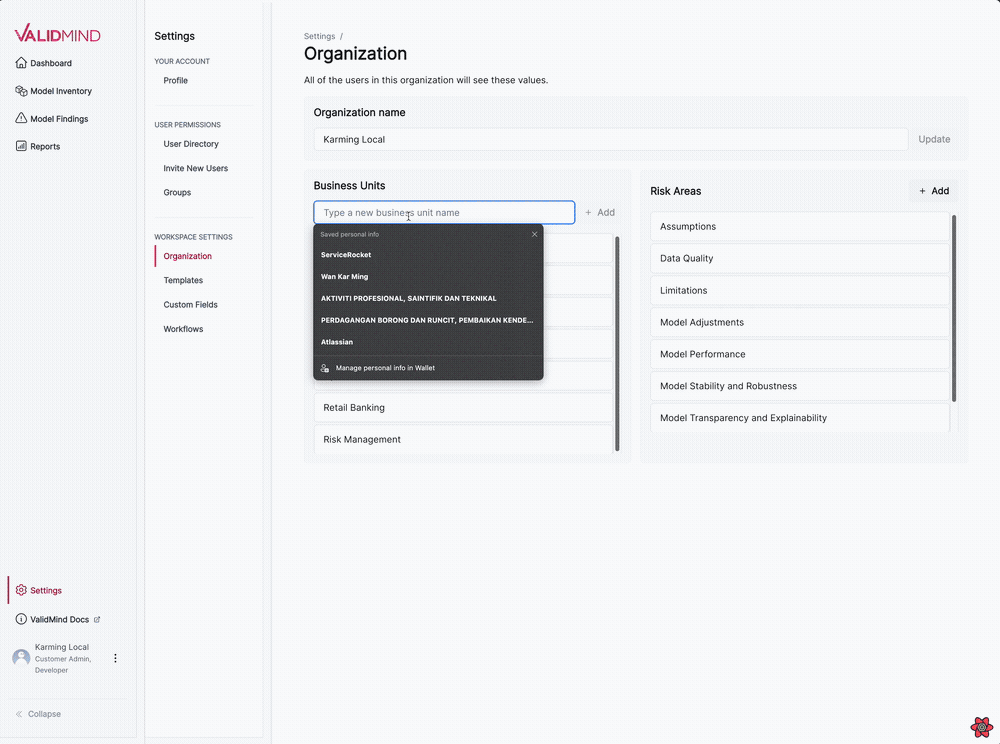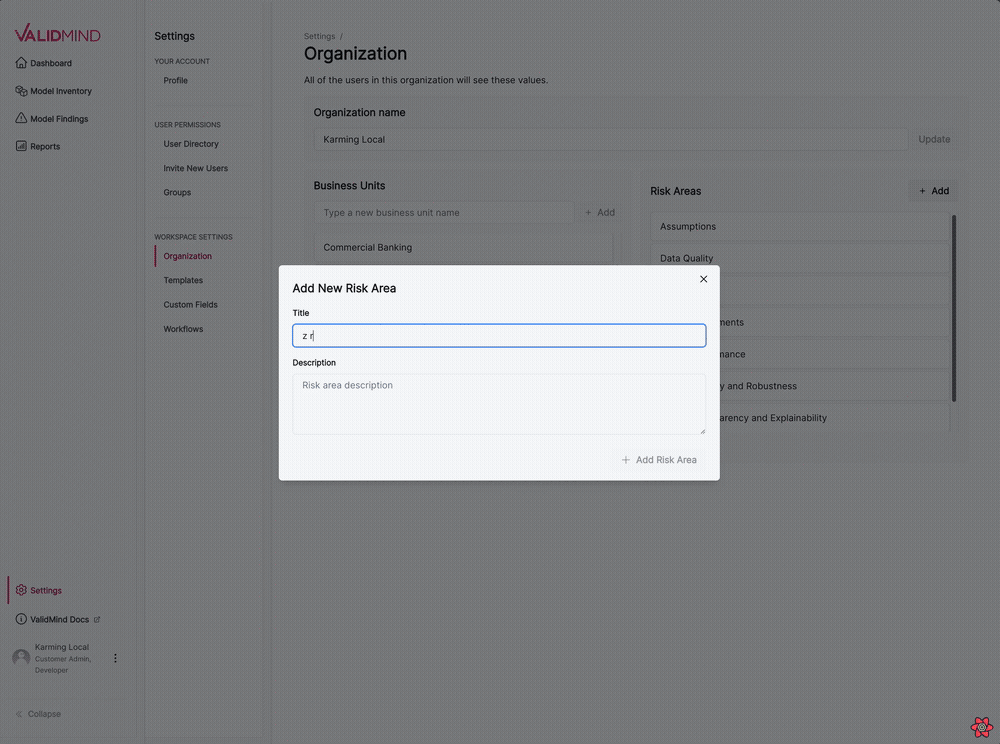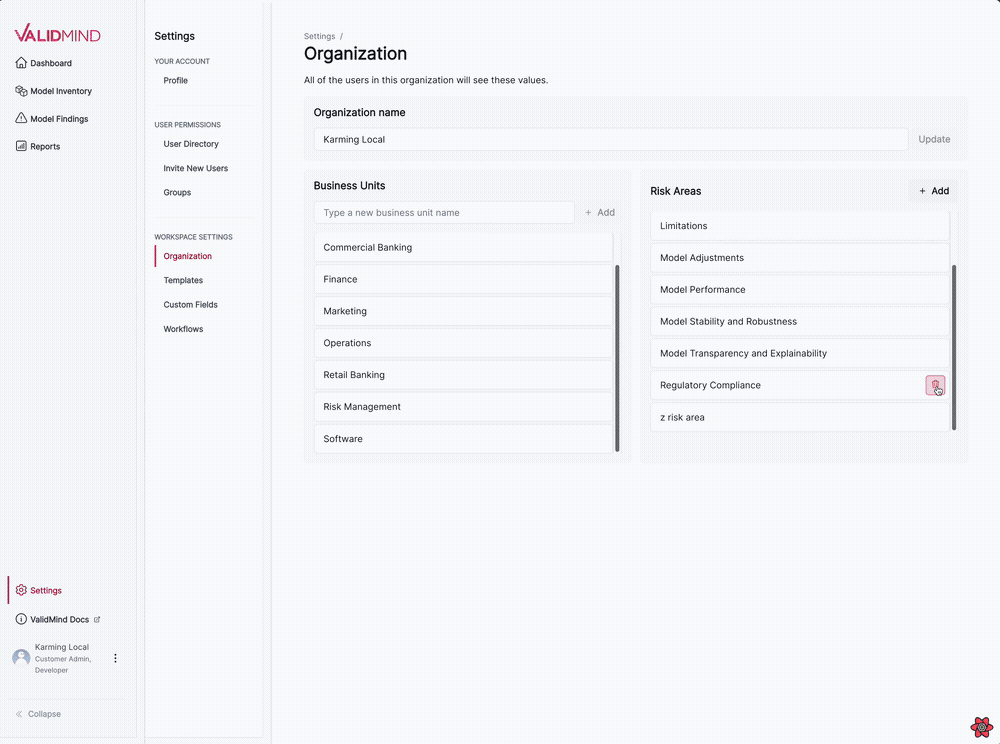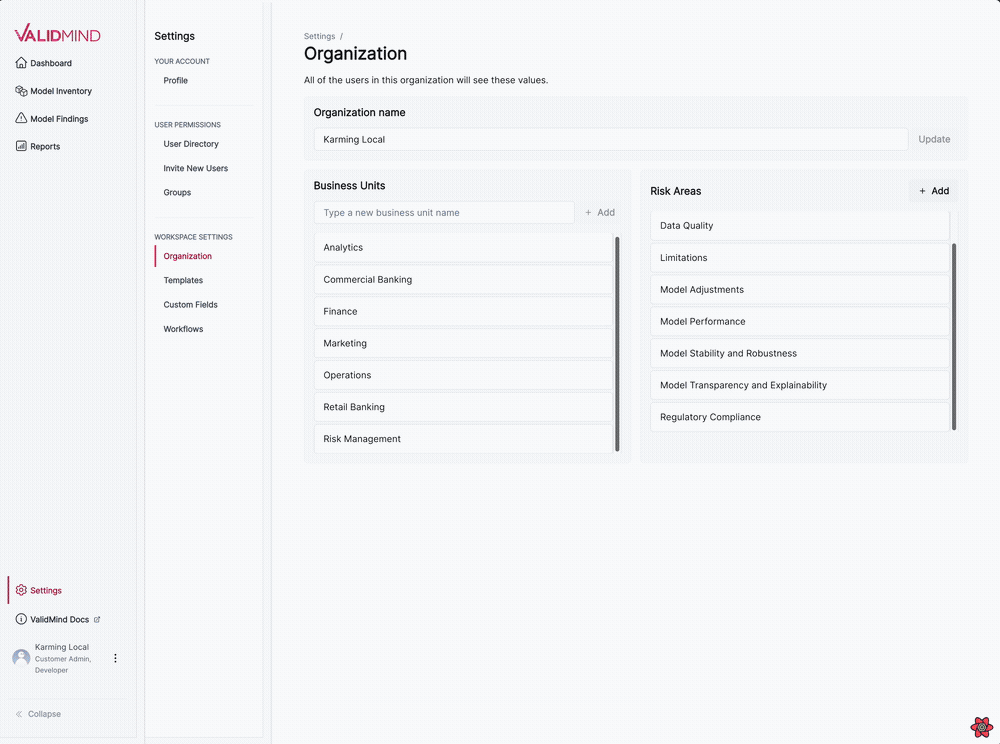
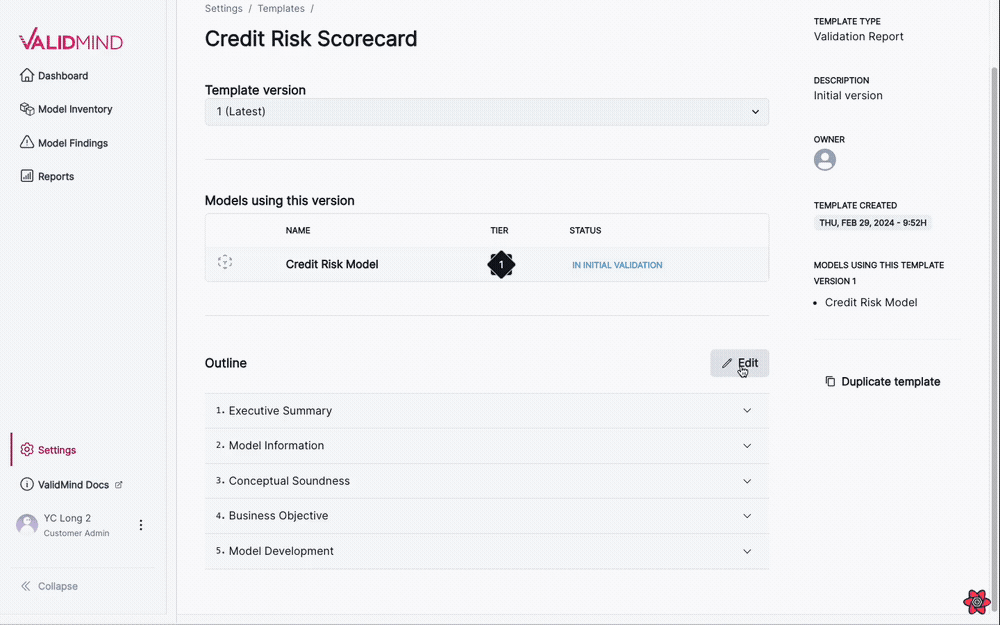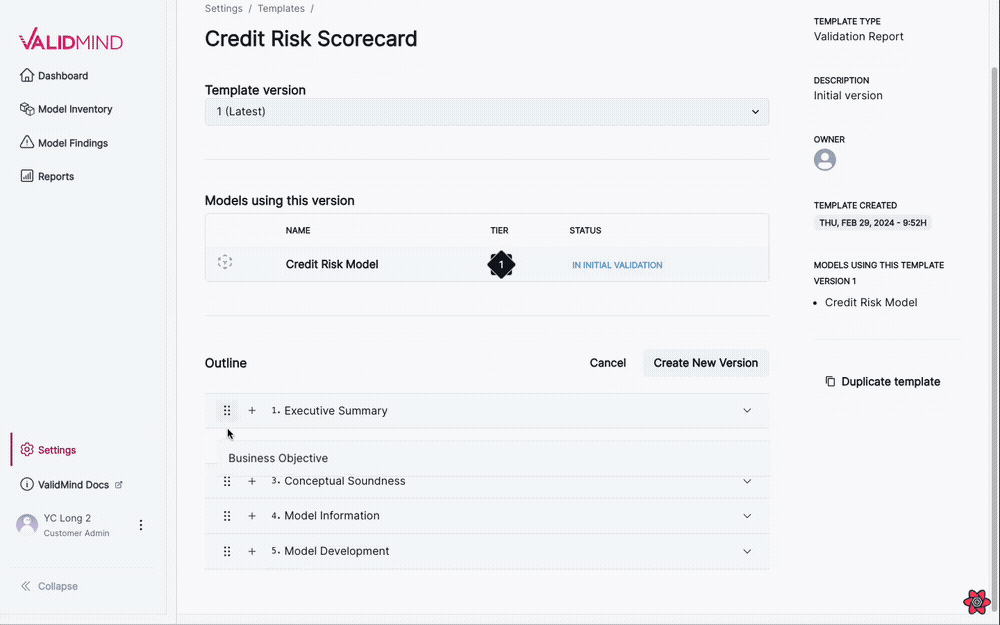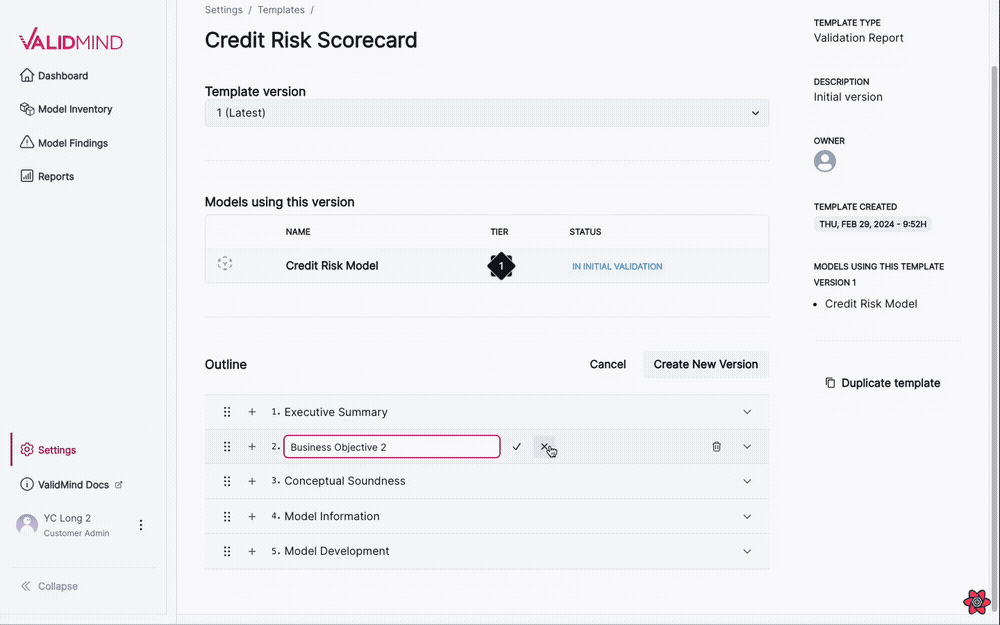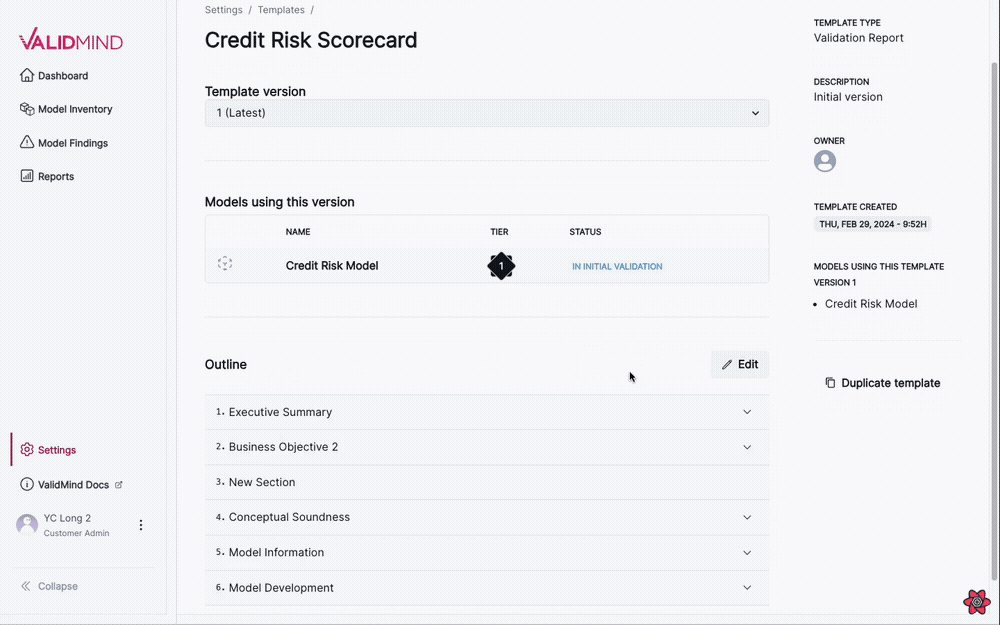
This new visual editing interface streamlines the template editing process, making it more intuitive and user-friendly:
We added support for two new VMDataset methods:
add_extra_column()get_extra_column()add_extra_column()You can now register arbitrary extra columns in a dataset when a test needs to compute metrics outside of the existing sets of columns (features, targets, predictions).
scores is needed for computing the metrics.Example usage:
# Init your dataset as usual
vm_train_ds = vm.init_dataset(
dataset=train_df,
input_id="train_dataset",
target_column=customer_churn.target_column,
)
# Generate scores using a user defined function:
scores = compute_my_scores(x_train)
# Assign a new "scores" column to vm_train_ds:
vm_train_ds.add_extra_column("scores", scores)This function returns an error if no column values are passed:
vm_train_ds.add_extra_column("scores")
ValueError: Column values must be provided when the column doesn't exist in the datasetIt’s also possible to use init_dataset with a dataset that has precomputed scores, for example:
> train_df.columns
Index(['CreditScore', 'Gender', 'Age', 'Tenure', 'Balance', 'NumOfProducts',
'HasCrCard', 'IsActiveMember', 'EstimatedSalary', 'Exited',
'Geography_France', 'Geography_Germany', 'Geography_Spain'],
dtype='object')> train_df["my_scores"] = scores
> train_df.columns
Index(['CreditScore', 'Gender', 'Age', 'Tenure', 'Balance', 'NumOfProducts',
'HasCrCard', 'IsActiveMember', 'EstimatedSalary', 'Exited',
'Geography_France', 'Geography_Germany', 'Geography_Spain',
'my_scores'],
dtype='object')Make sure you set the feature_columns correctly:
vm_train_ds = vm.init_dataset(
dataset=train_df,
input_id="another_ds",
feature_columns=[
"CreditScore",
"Gender",
"Age",
"Tenure",
"Balance",
"NumOfProducts",
"HasCrCard",
"IsActiveMember",
"EstimatedSalary",
"Exited",
"Geography_France",
"Geography_Germany",
"Geography_Spain",
],
target_column=customer_churn.target_column,
)Then, call add_extra_column() to register the extra column:
> another_ds.add_extra_column(column_name="my_scores")
Column my_scores exists in the dataset, registering as an extra columnget_extra_column()You can use this inside a test to retrieve the extra column values.
Example usage:
scores = self.inputs.dataset.get_extra_column("scores")ValidMind now supports the ability to compose multiple Unit Tests into complex outputs.
The following tests for text data validation have been added:
We added new decorators to support task type and tag metadata in functional metrics.
Usage example:
from sklearn.metrics import accuracy_score
from validmind import tags, tasks
@tasks("classification")
@tags("classification", "sklearn", "accuracy")
def Accuracy(dataset, model):
"""Calculates the accuracy of a model"""
return accuracy_score(dataset.y, dataset.y_pred(model))
# the above decorator is syntactic sugar for the following:
Accuracy.__tags__ = ["classification"]
Accuracy.__tasks__ = ["classification", "sklearn", "accuracy"]We added support for assigning prediction_probabilities to assign_predictions. This support enables you to:
You can now associate model findings with sections within your model documentation. Doing so will allow you to track findings by severity, section-by-section, in the Document Overview page.
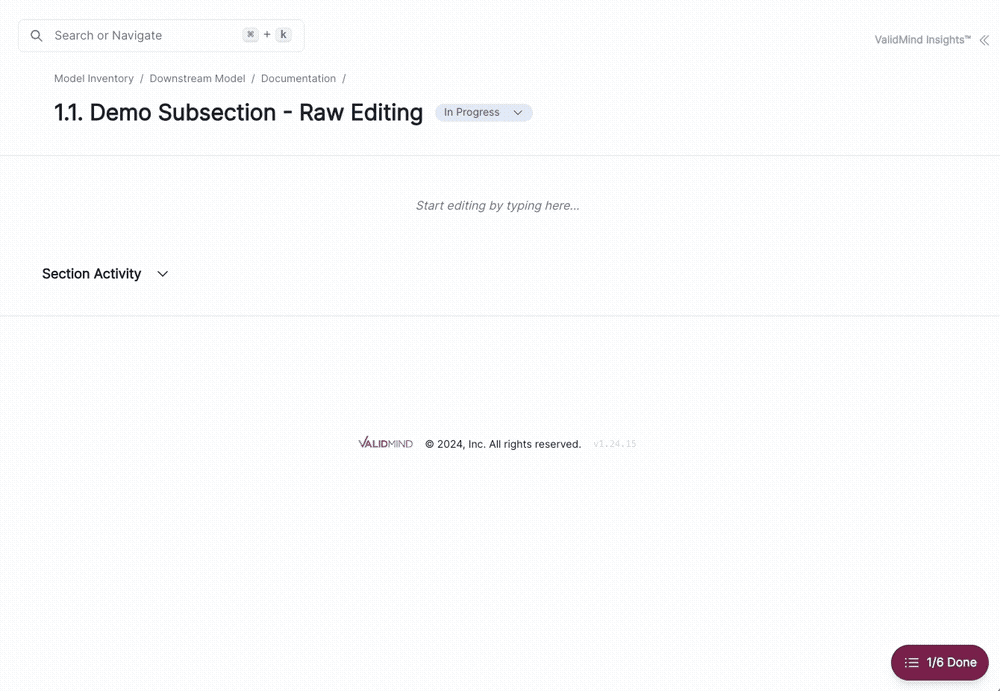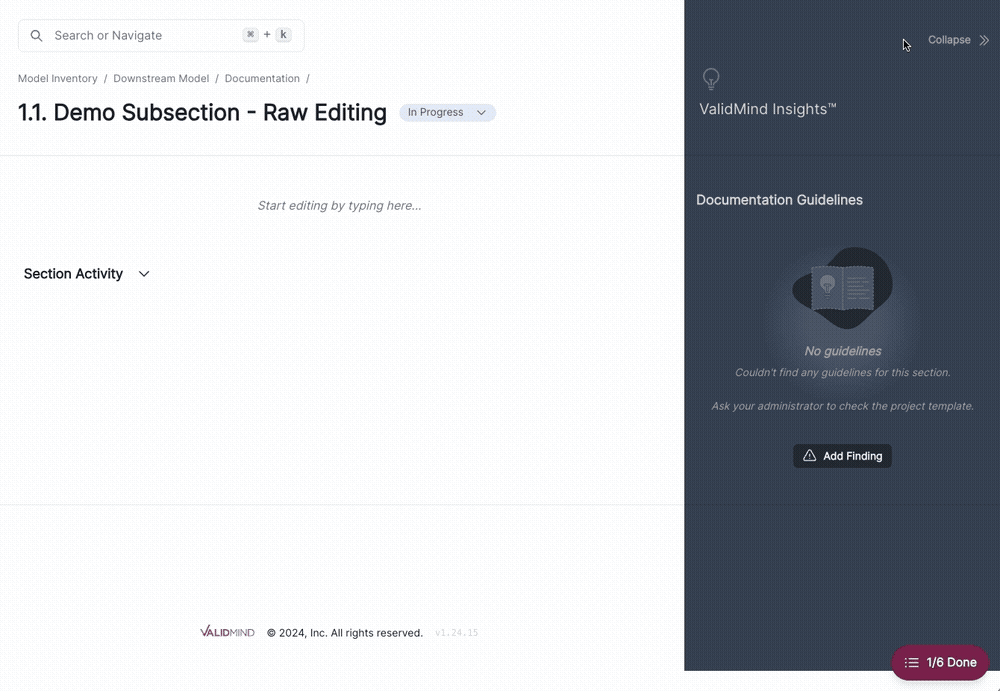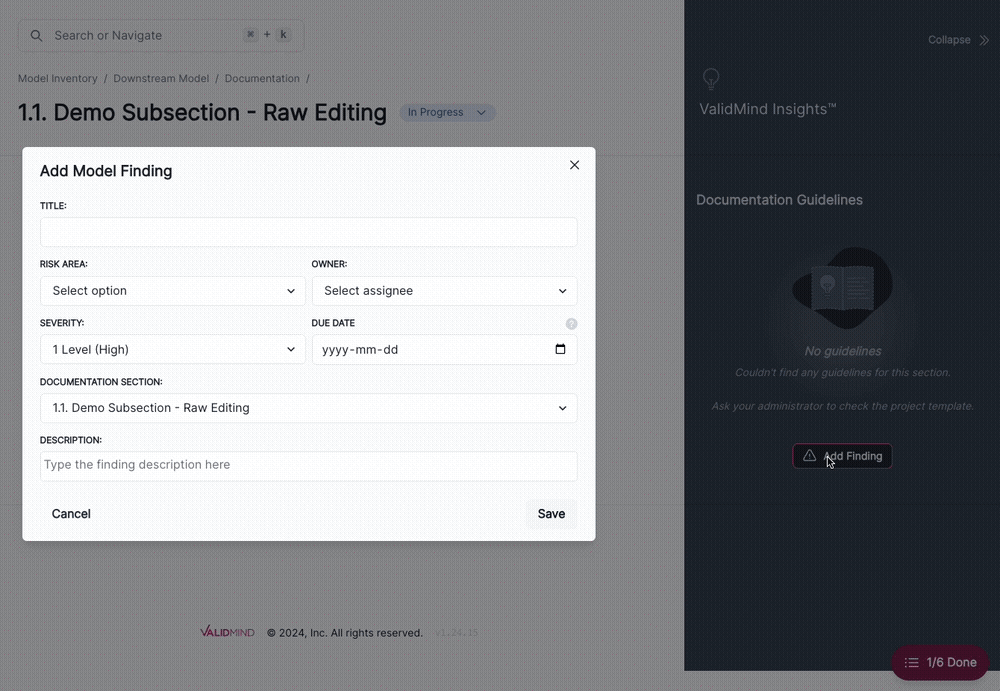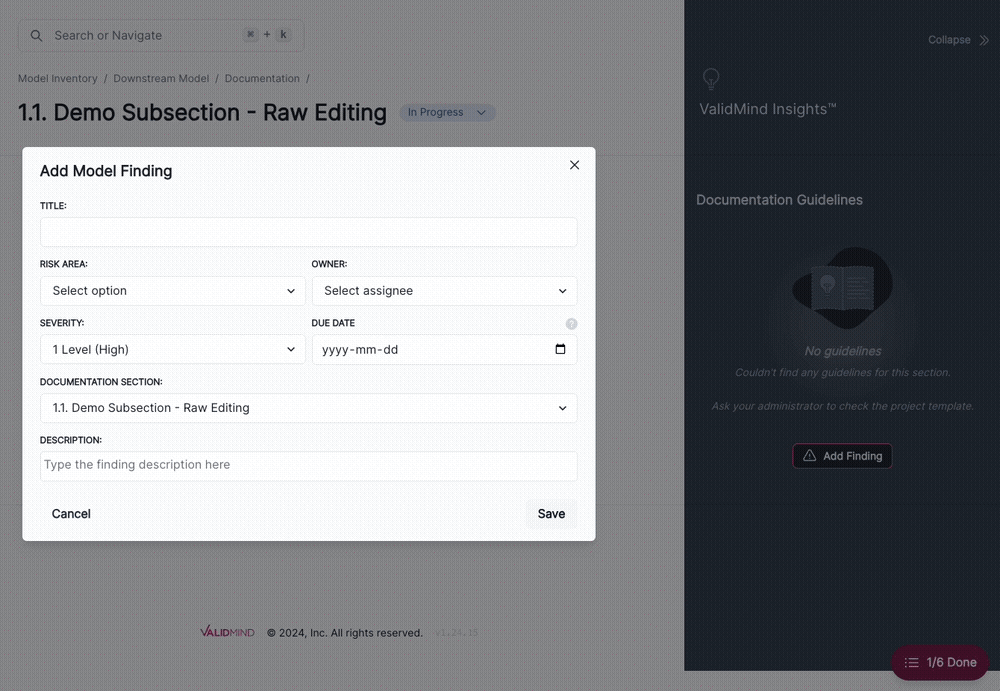
Our revamped workflows configuration enables more granular management of model and documentation lifecycles and deep integration with model inventory attributes.
The new workflows configuration includes the following features:
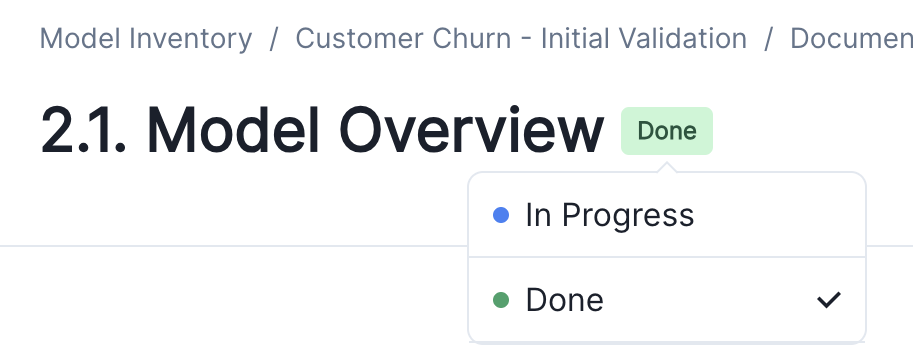
We added a status picker to each section of the model Documentation page.
We added a new property to the Long Text inventory field type: enable rich text formatting
We created a new Validation Report overview page which shows a section-by-section outline of a model’s validation report, including a total compliance summary for all risk areas associated with the model.
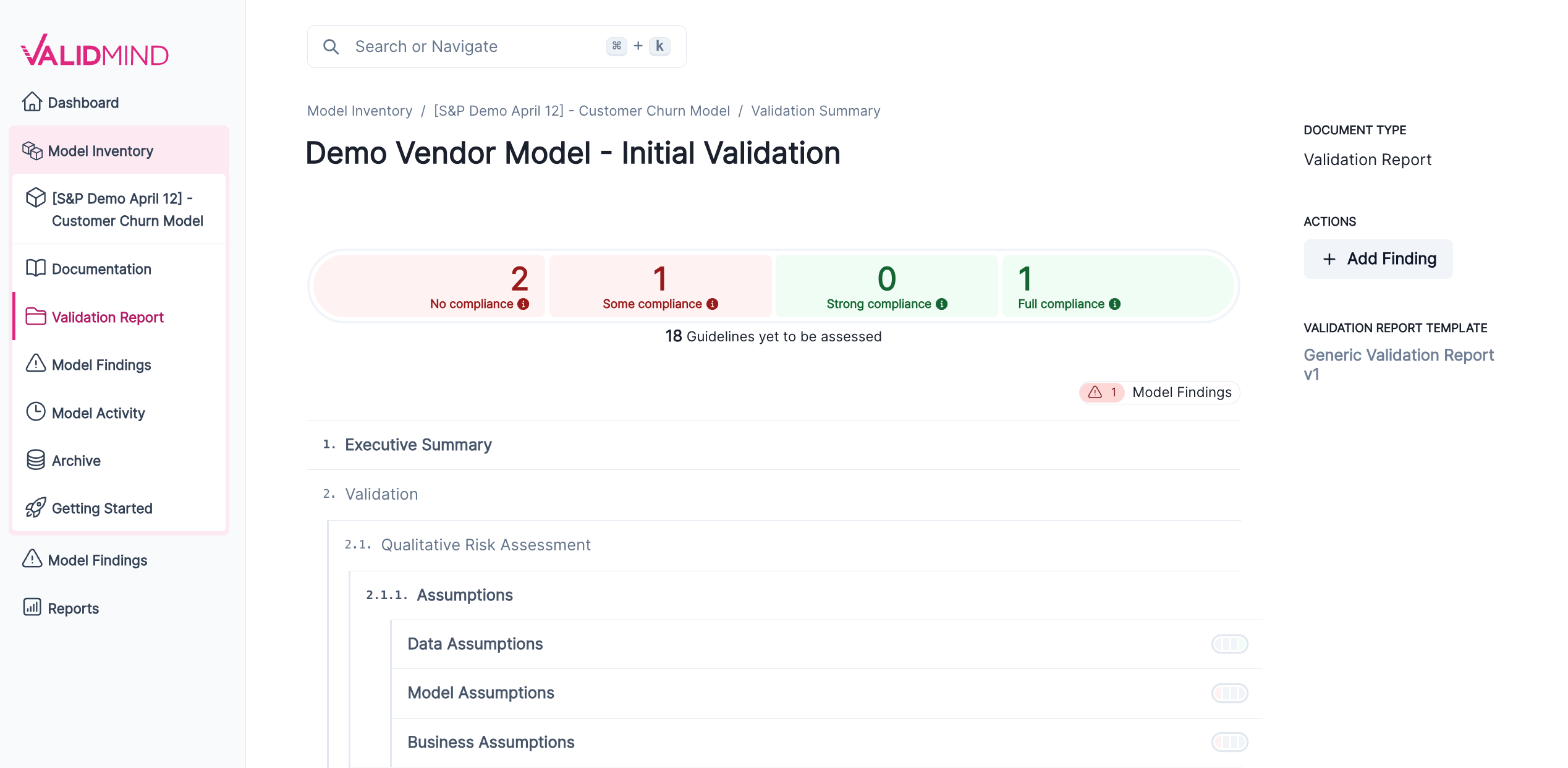
We added the ability to flag models as is vendor model and specify a vendor name during model registration.
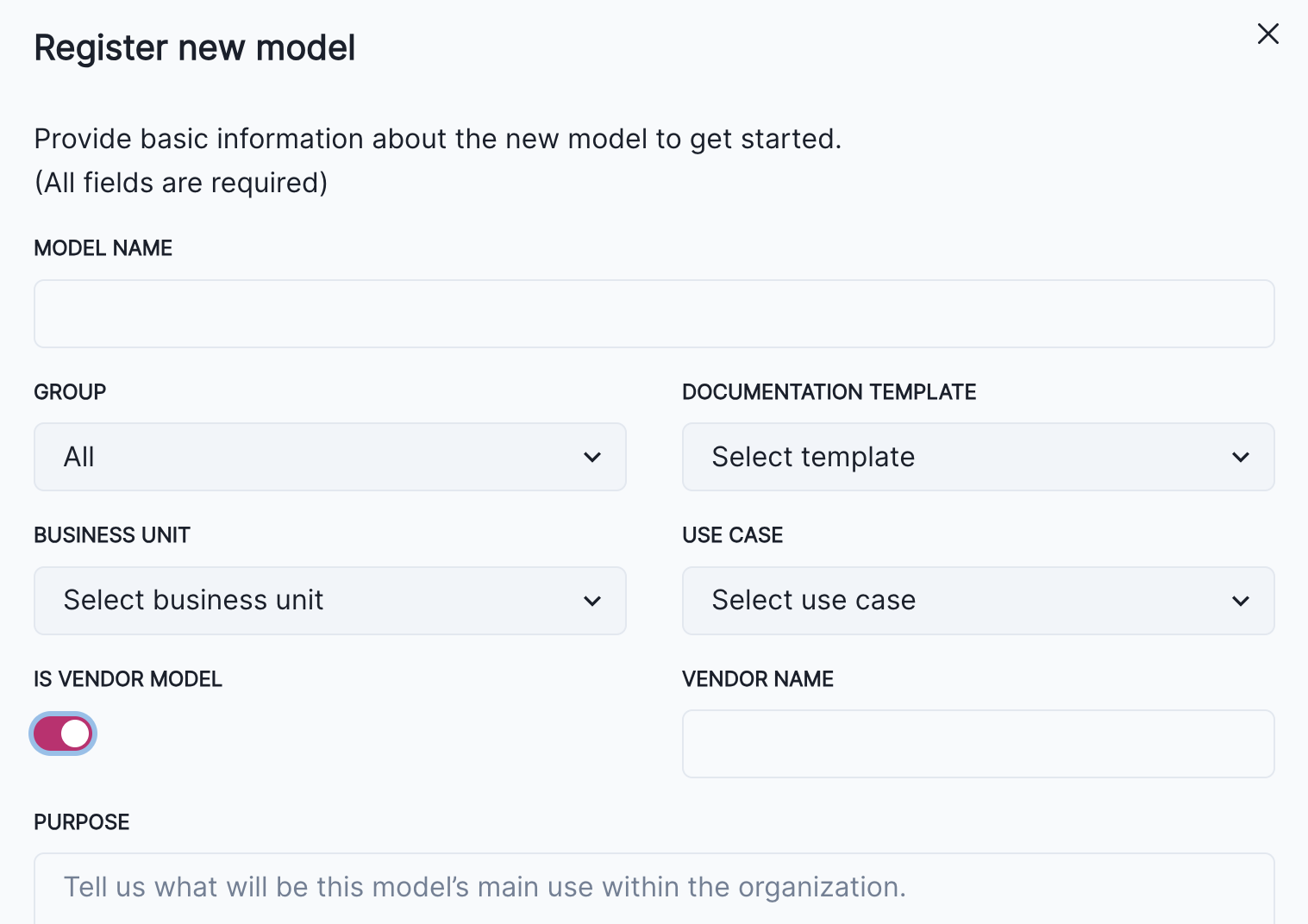
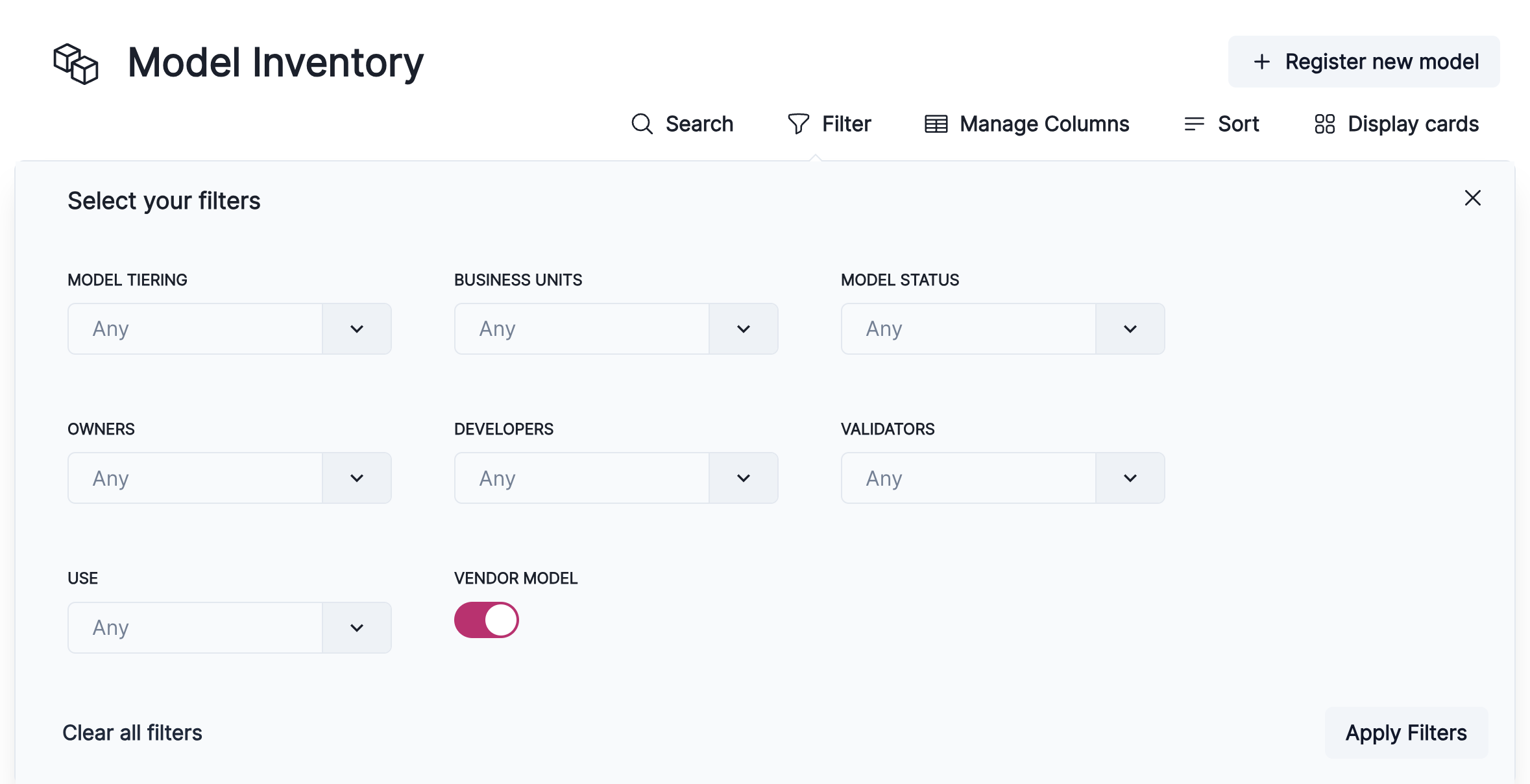
Also available is an improved look and functionality for filtering the Inventory.
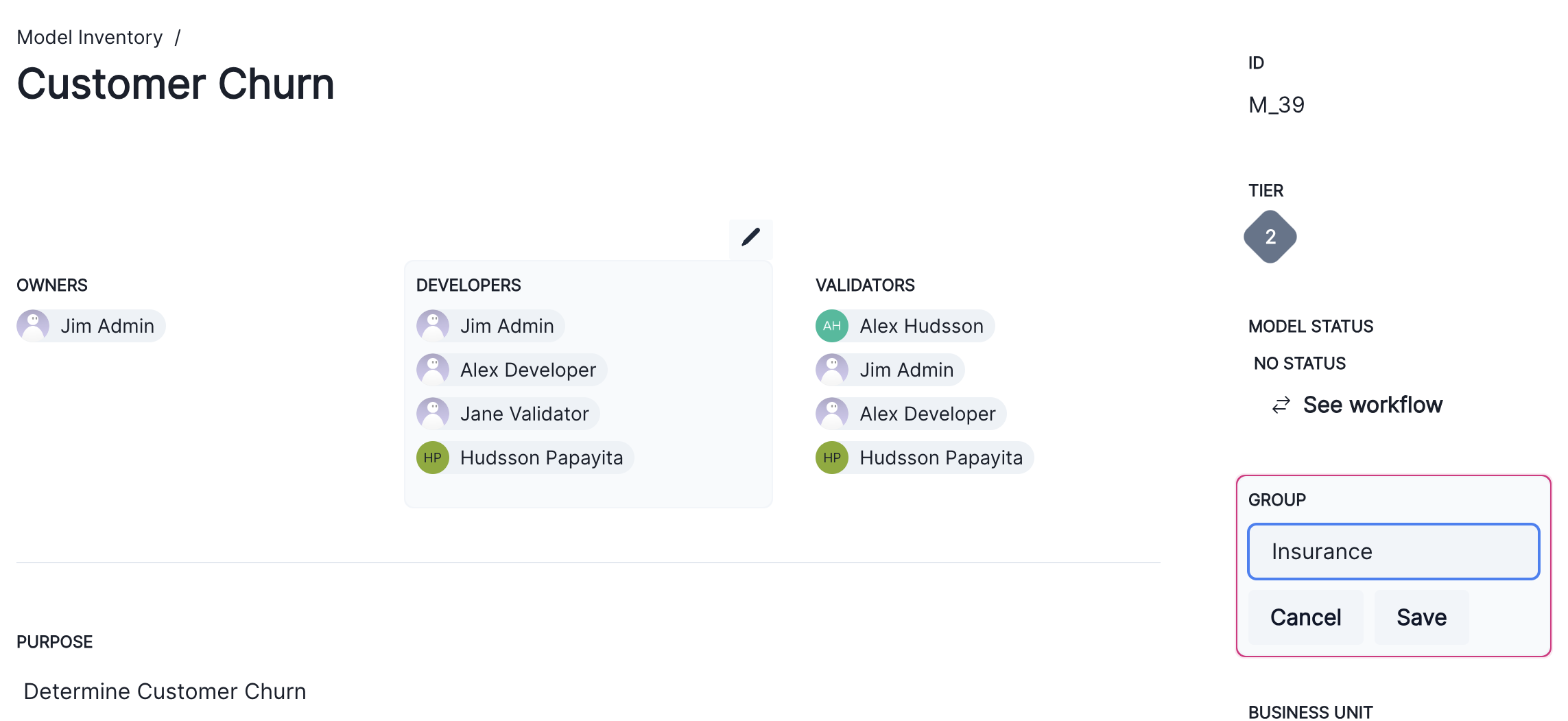
You can now modify the group the model belongs to.
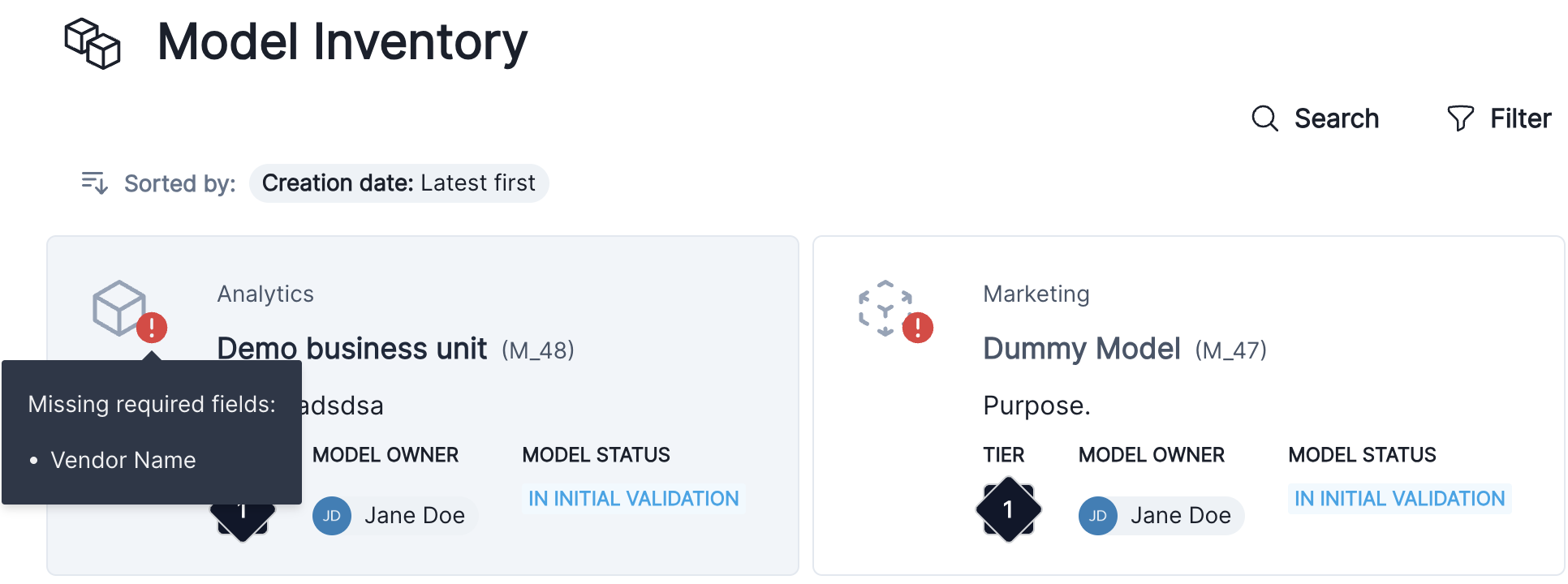
We added a tooltip for required missing fields on the Inventory card view.
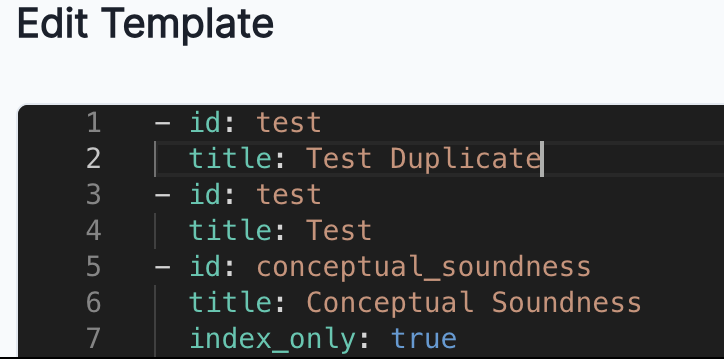
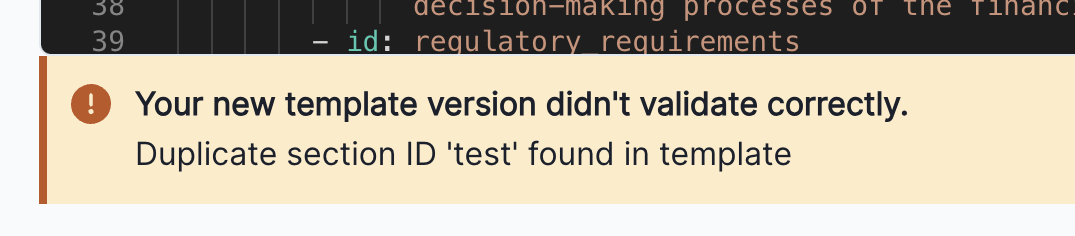
We now validate whether a template has duplicate section IDs and return an error if a duplicate ID is found.
Many of our Jupyter Notebooks have received improvements to make them easier to consume and more standalone:
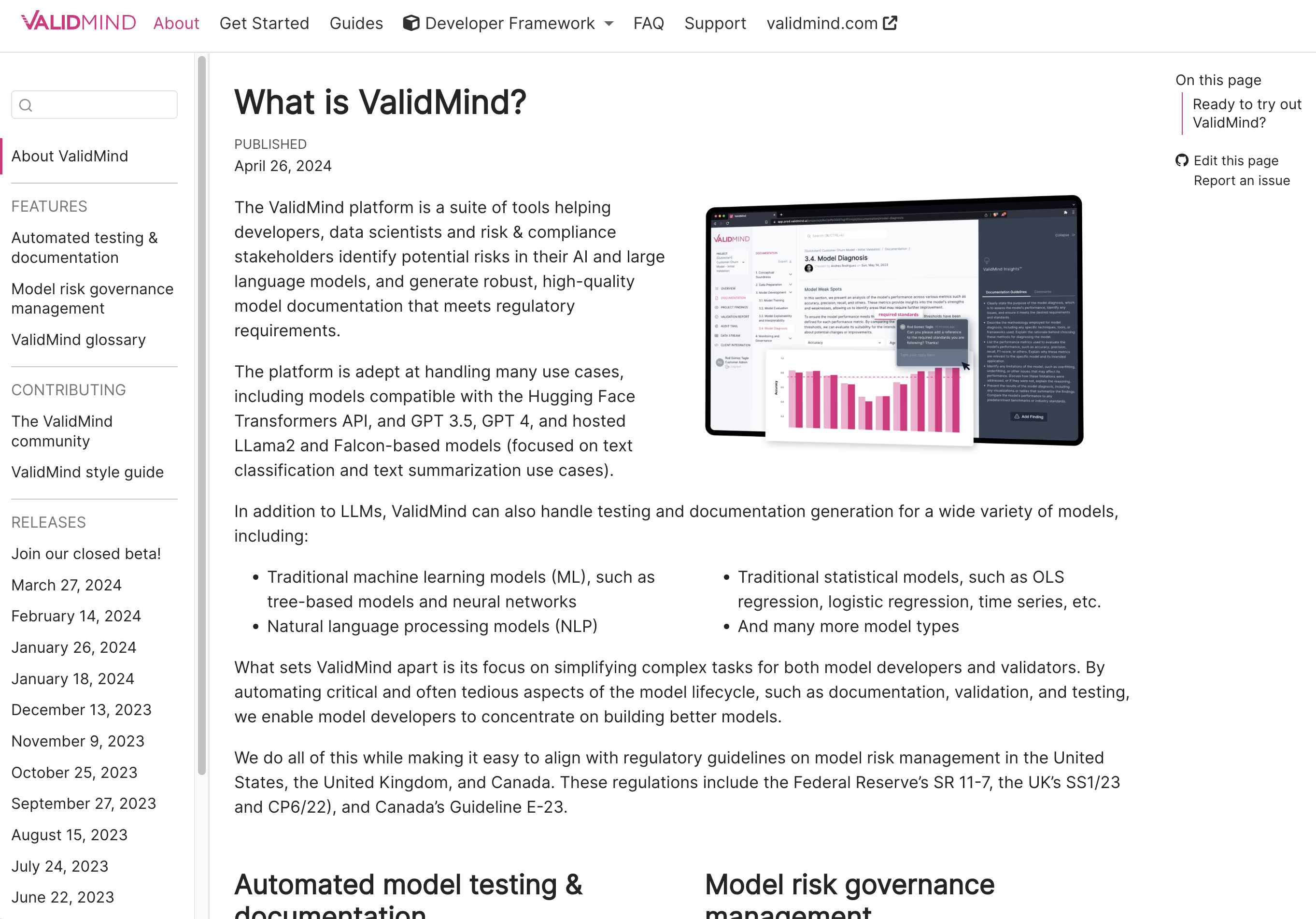
We’ve revamped our documentation for a cleaner, more intuitive experience. The update features a brand new About section:
Find a brand new set of guides on contributing to our open source software. Learn how to engage with the ValidMind community, read about our brand voice and vision, and more:
Check out the first official version of the ValidMind style guide!
We reworked our quickstart experience to shorten the number of clicks it takes to get you started.
You can now access the quickstart directly from the homepage of our docs site, where we direct you to the preferred quickstart on JupyterHub right away.
A new three-minute video walks you through documenting a model with ValidMind and is now included in the quickstart for JupyterHub:
We added getting started information for the new ValidMind sandbox environment, which is currently available on request. You can use the sandbox to gain hands-on experience and explore what ValidMind has to offer.
The sandbox mimics a production environment. It includes comprehensive resources such as notebooks with sample code you can run, sample models registered in the model inventory, and draft documentation and validation reports.
Most of our model documentation features are available for you to test in the sandbox. These include:
These features provide a rich context for testing and evaluation. You can use realistic models and datasets without any risk to your production environment.
To access the latest version of the ValidMind Platform,2 hard refresh your browser tab:
Ctrl + Shift + R OR Ctrl + F5⌘ Cmd + Shift + R OR hold down ⌘ Cmd and click the Reload buttonTo upgrade the ValidMind Library:3
In your Jupyter Notebook:
Then within a code cell or your terminal, run:
%pip install --upgrade validmindYou may need to restart your kernel after running the upgrade package for changes to be applied.